LitXBench
I think that the lack of experimental materials science datasets/evals is holding the field back:
- It's hard to benchmark your simulation workflows without experimental data.
- If you're trying to discover something novel, you need to "beat the best". But how can you assign an RL reward if you don't know the true Pareto front? (This matters because pretraining distributions are out of most people's control.)
We need modestly large datasets, but scaling self-driving labs will take time. So in the interim, we need a method to validate computational approaches. One pragmatic approach to accomplishing these goals is to extract and index experiments from the scientific literature. This is because thousands of experiments are recorded in papers, and mining them is much cheaper (and scalable) than performing the experiments yourself, even if the measurements are noisy.
The obvious approach is to use LLMs to extract experimental information into a structured (and indexable) data format. But I couldn't find a reliable benchmark to test my approach. I used a few human-annotated datasets for validation, but found that LLMs were more correct than my validation set. I realized that we needed a new kind of benchmark that properly captures the complexity of experimental data.
What is LitXBench?
It's a framework to benchmark how well we can extract experiments from papers. It also contains LitXAlloy, a LitXBench-based benchmark that contains manually-extracted experiments from 19 alloy papers. It's quite dense, with 1426 datapoints and an average of 74.8 extracted measurements per paper.
We define an experiment as a set of experimentally synthesized materials, which we define by all their processing steps and measured properties.

To properly differentiate materials from each other, LitXBench solely identifies materials by their processing conditions, rather than by their composition. This is because a material can have multiple characterized compositions from different machines (e.g. by scale, by EDS, by XRF). It's important to include them all.
LitXBench Represents Extracted Materials as Code

Why code? Because it's much more human-readable than JSON. A big reason why most annotated datasets/benchmarks are inaccurate is that it's hard to verify and fix errors. But code is designed to be editable and readable (unlike CSV or JSON).
Another advantage is that we can use code to help us compute and normalize variables. Consider this paper, where the authors added equiatomic Tungsten Carbide particles to a base CoCrFeNi alloy. The amount of these additions is equal to 10% by weight of the base alloy. The nominal composition they made is CoCrFeNiW0.12C0.12. But it's hard for humans to look at this and know if these numbers are correct! What we really need is a function to do this for us.

Code shifts verification away from calculating the correct composition to verifying the correctness of the function that performs the calculation. By making the benchmark more auditable, it becomes more trustworthy.
Code also enables validation, as compile and runtime errors teach LLMs to retry when they make mistakes. More importantly, we can perform semantic checks such as ensuring that: 'no alloy can depend on itself as a precursor' (no cycles in the graph). We can also perform checks specifically for our material class. For example, all "cut" events must be performed after an alloy has "cooled down". These semantic checks ensure that data is extracted in a consistent manner.
Code enabled LitXBench to be thoroughly reviewed for accuracy. After many hours of manual review, I also used LLMs to validate the benchmark's correctness (all LLM suggestions were heavily scrutinized by humans before the benchmark was updated). I spent an estimated 1.1 billion Opus 4.5/4.6 tokens within Claude Code and used many more Gemini 3.1 and GPT-5.2-codex tokens to help catch errors. Correcting these mistakes took many hours, and it taught me that human-annotated datasets shouldn't be held in such high regard, as errors are quite common.
Results
Further results and experiments are in the paper, and on the public leaderboard. If you're interested, here are the results of frontier LLMs on LitXAlloy:
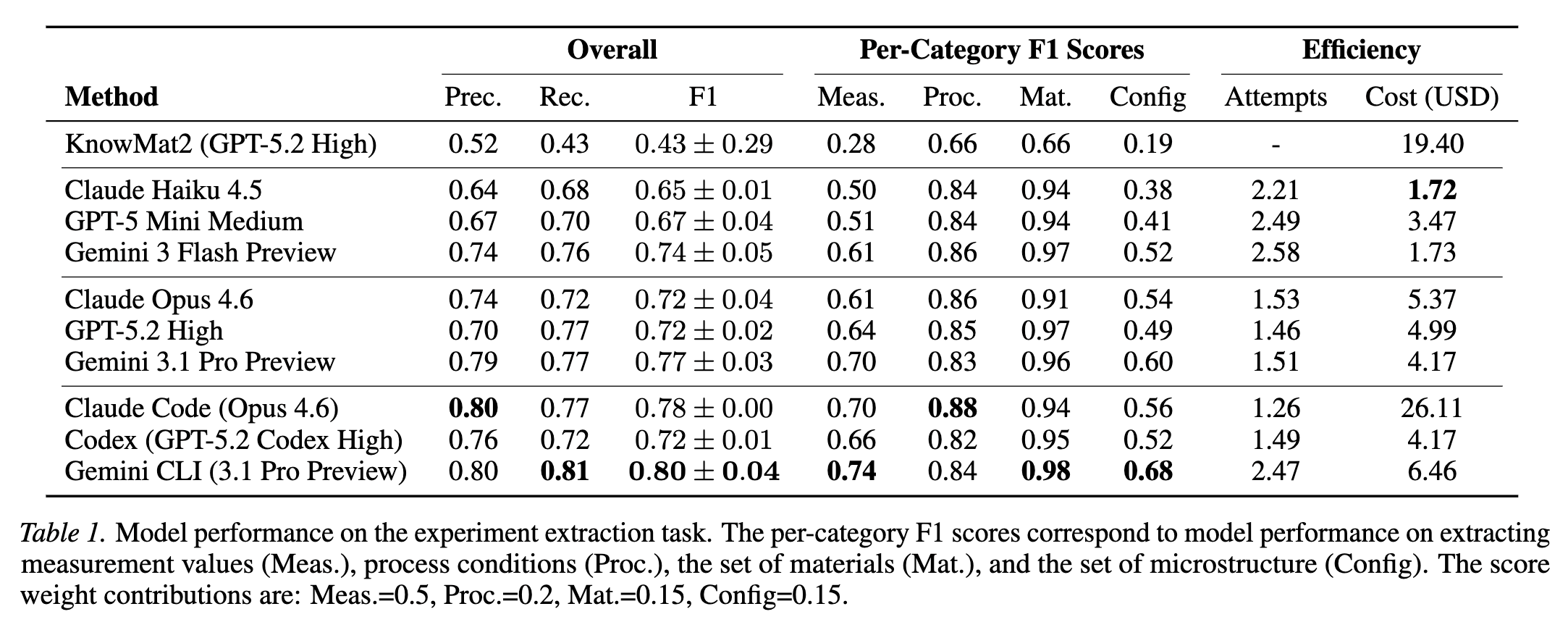
Overall, LLMs are proficient at experiment extraction, but more work is needed before experimental data is truly reliable. I'm just glad that we now have a quantifiable metric for "extraction error". I hope LitXBench will be used to create novel, meaningful datasets/benchmarks that don't currently exist.
- Curtis